| 数据挖掘专题 | 您所在的位置:网站首页 › json file是什么 › 数据挖掘专题 |
数据挖掘专题
|
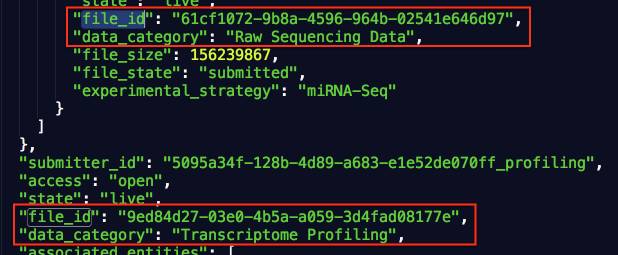
3、每个样本有两个file_id,其中第二个与465个文件夹中的一致:
4、file_name对应 file_id 文件夹下的表达数据文件:
5、此处的 submitter_id即为常见的TCGA样本名:
综上,基于 file_id、file_name、submitter_id 即可完成表达数据文件与样本名称的对应,例如之前下载的TCGA-COAD的miRNA数据,TCGA_GDC/COAD/miRNA/f457196a-04ef-46f4-addc-3c698208f4d4/ac35e037-f717-401d-8021-a8e3a7b0b368.mirbase21.mirnas.quantification.txt,我们来详细看下这个目录结构。 f457196a-04ef-46f4-addc-3c698208f4d4 即为Metadata中的 file_id,ac35e037-f717-401d-8021-a8e3a7b0b368.mirbase21.mirnas.quantification.txt即为Metadata中的 file_name,由此可通过json检索到其存储的样本对应的submitter_id 为 TCGA-AA-A00W-01A。 思路理清之后就可以开始进行数据整理了,可以提取每个样本的原始count值,或者RPM值,最终格式如下:
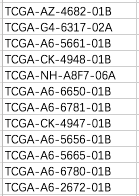
样本共计465列,其中样本名: 1、以 -11A 结尾的8列,无重复,且均有对应的 -01A 样本; 2、以 -01A 结尾的445列,有4个样本重复,去重后还有441列,重复的样本:TCGA-A6-6650-01A;TCGA-A6-6781-01A;TCGA-A6-6780-01A;TCGA-A6-5656-01A 3、剩下的12列中,02表示是复发肿瘤、06表示转移,01B表示重复样本:
其中3个样本 TCGA-AZ-4682-01B;TCGA-CK-4948-01B;TCGA-CK-4947-01B 无对应的 -01A 样本。 综上,case数为444个(441+3,可以理解为去重后-01A结尾样本的个数),数据初步整理后与数据下载时显示的Files数和Cases数一致! 对于重复样本(同一个患者/case,多个肿瘤样本/file),以患者TCGA-A6-6650为例,共有3个重复,分属下载的3个文件,共有同一个case_id:
不同的file_name,相同的case_id:
所以,我们会看到在下载数据的时候,files数要大于cases数,这就解释了我们在 TCGA表达数据下载(一)中抛出的第一个问题! 目前对待重复样本,比较主流的方法是只保留一个:
所以在TCGA数据分析中,最常用的两类样本是 -01A 和 -11A 结尾的样本,分别代表肿瘤和正常样本,不同数字编码代表的意义,部分如下:
更多标识详见:https://gdc.cancer.gov/resources-tcga-users/tcga-code-tables/sample-type-codes 最终,我们将TCGA-COAD的miRNA表达数据整理成如下,1881个前体miRNA在449个样本中的表达值数据: 好像我们顺带又把 TCGA表达数据下载(一)中抛出的第四、五这两个问题解决了~ 各位读者: 科研小助手官方QQ群:93646661amateur_1988为好友,加入科研小助手官方微信群。申请加好友请备注姓名和单位。 amateur_1988为好友,加入科研小助手官方微信群。申请加好友请备注姓名和单位。返回搜狐,查看更多 |







【本文地址】